Avoiding Unintended Synchronization
Video Summary
The below video is a short summary of the article in presentation format. Read on for more details and also links to related work and example codes.
Background
This is the first in a series of articles on MPI Best Practices for Performance. The initial topic is on avoiding unintended synchronization when performing communication using MPI. In particular, we look at using MPI point-to-point communication to send and receive data between MPI processes. Consider a common two-dimensional halo exchange where each process sends and receives messages with up to four of its neighbors.
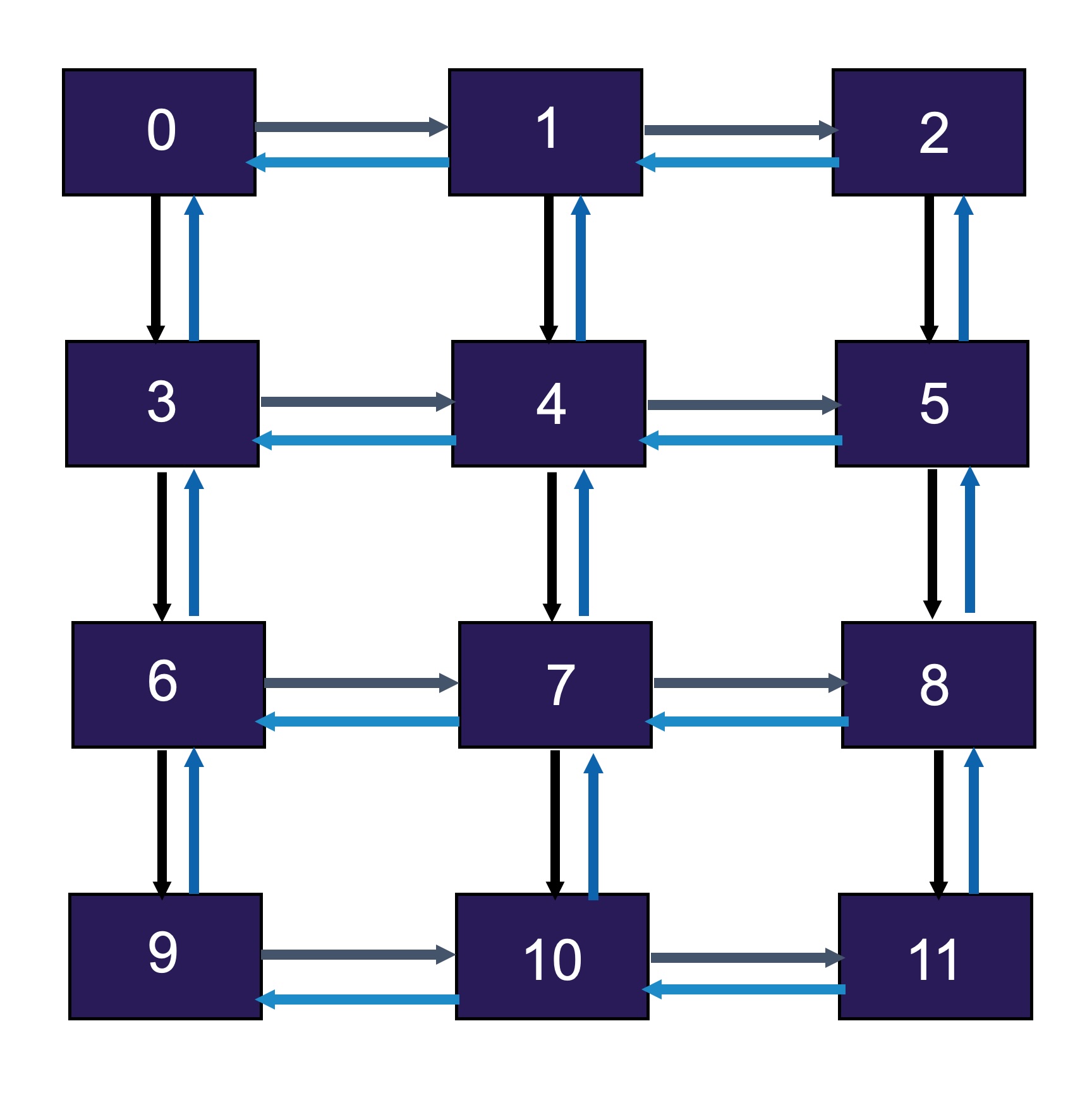
Examples
We will look at four different implementations of such an exchange and examine the performance aspects of each, as well as some common pitfalls. Source code for each example can be found here. First, a naive implementation where each process first sends, then receives data to/from each of its neighbors.
Example 1 (Deadlock!)
MPI_Send(sbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD);
MPI_Send(sbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD);
MPI_Send(sbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD);
MPI_Send(sbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD);
MPI_Recv(rbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(rbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(rbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(rbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
We show this version as an example of what NOT to do when implementing your data exchange with MPI. The reason is that this version is unsafe. The reason is that MPI is not required to buffer send data for the user. In other words, MPI may wait until a receive buffer has been posted before transmitting and completing a send operation. In the example above, every process starts by sending data, and if no receive buffers are posted, they could be stuck waiting for those sends to complete indefinitely!
Next, we look at one possible solution by carefully ordering the operations so there is no chance that all processes can be sending at the same time:
Example 2
if (south != MPI_PROC_NULL) {
MPI_Send(sbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD);
}
if (north != MPI_PROC_NULL) {
MPI_Recv(rbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
if (east != MPI_PROC_NULL) {
MPI_Send(sbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD);
}
if (west != MPI_PROC_NULL) {
MPI_Recv(rbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
if (north != MPI_PROC_NULL) {
MPI_Send(sbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD);
}
if (south != MPI_PROC_NULL) {
MPI_Recv(rbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
if (west != MPI_PROC_NULL) {
MPI_Send(sbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD);
}
if (east != MPI_PROC_NULL) {
MPI_Recv(rbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
While this will resolve the deadlock issues that exist in the first example, it is tricky to implement and results in sequentialization of communication. The ordering above means that only processes on the bottom of the grid will be in receive mode to start. Only after those receive operations complete will the next row from the bottom post their receives, and so on. Thereby each data exchange happens sequentially by row or column. Any opportunity for communication overlap is lost.
The next step we will take to improve our exchange is to use nonblocking receive operations and post them all before starting our send operations.
Example 3
MPI_Irecv(rbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv(rbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD, &reqs[1]);
MPI_Irecv(rbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD, &reqs[2]);
MPI_Irecv(rbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD, &reqs[3]);
MPI_Send(sbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD);
MPI_Send(sbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD);
MPI_Send(sbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD);
MPI_Send(sbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD);
MPI_Waitall(4, reqs, MPI_STATUSES_IGNORE);
Consider this execution trace (made using HPC Toolkit) of the above method. Processes which receive messages from multiple neighbors simultaneously become congested. This congestion introduces delays into the exchange. Sender processes wait for a congested receiver to process incoming messages. In our example, delays will propagate throughout the exchange and lead to underutilization of the communication resources and suboptimal performance.
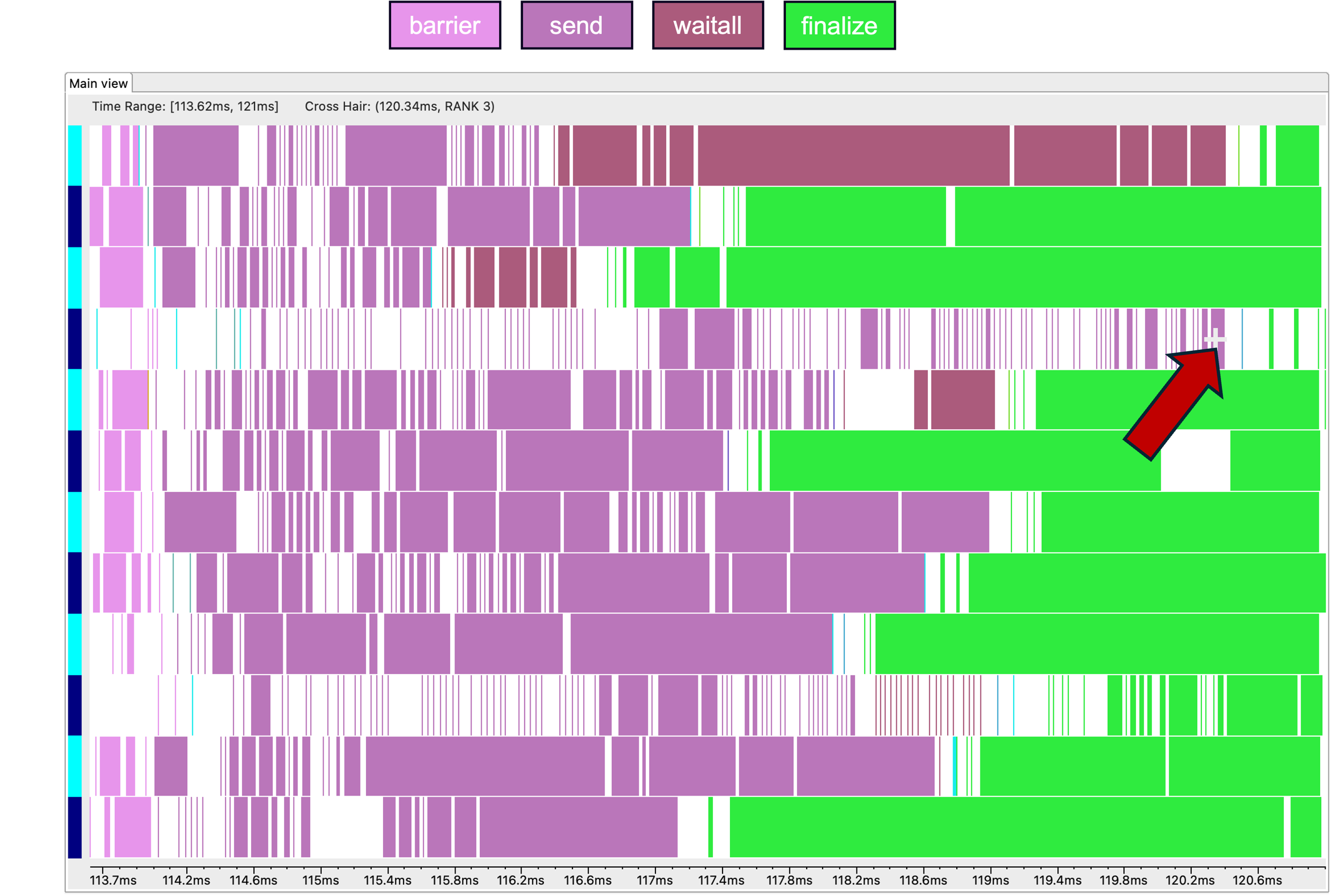
Preposting receive operations results in multiple positive outcomes. First, simpler code, which any developer can appreciate. Second is better performance. In our fully blocking example, receive operations and their complementary sends are rate limited by only posting them one at time. By first posting all the receive operations, processes can receive multiple messages at once1 and instead become limited by the available communication resources (e.g. network bandwidth). However we can take it one step further. The send operations in our exchange are independent from the receive operations at each process. There should be no issue overlapping them, thereby implementing a fully nonblocking exchange.
Example 4
MPI_Irecv(rbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv(rbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD, &reqs[1]);
MPI_Irecv(rbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD, &reqs[2]);
MPI_Irecv(rbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD, &reqs[3]);
MPI_Isend(sbufsouth, COUNT, MPI_INT, south, 0, MPI_COMM_WORLD, &reqs[4]);
MPI_Isend(sbufeast, COUNT, MPI_INT, east, 0, MPI_COMM_WORLD, &reqs[5]);
MPI_Isend(sbufnorth, COUNT, MPI_INT, north, 0, MPI_COMM_WORLD, &reqs[6]);
MPI_Isend(sbufwest, COUNT, MPI_INT, west, 0, MPI_COMM_WORLD, &reqs[7]);
MPI_Waitall(8, reqs, MPI_STATUSES_IGNORE);
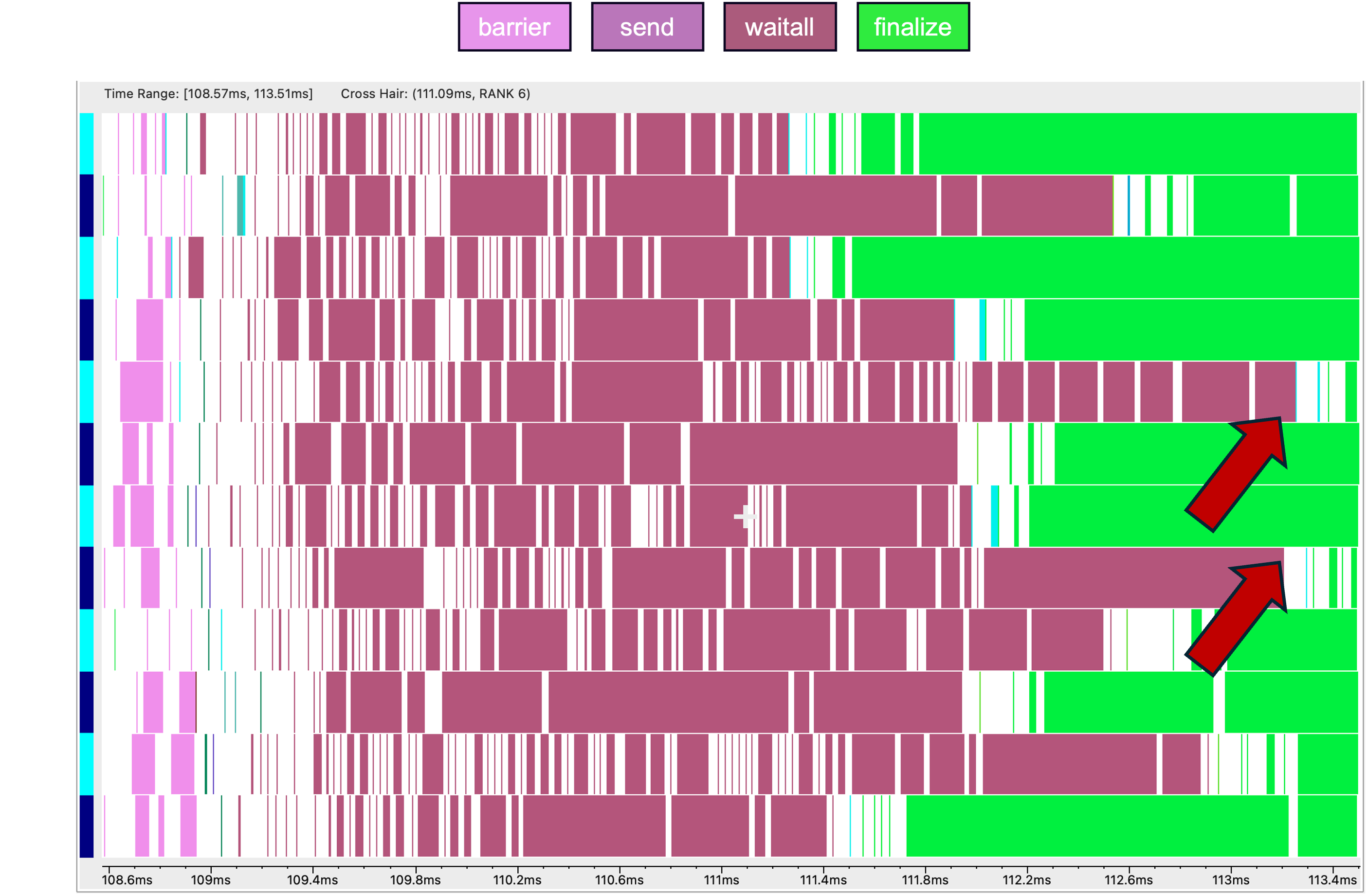
Starting all our sends before waiting for completion avoids any unnecessary synchronization or delay caused by congestion at a receiving process. The MPI runtime makes progress on all outstanding operations, resulting in a ~30% reduction in communication time compared to the previous trace using nonblocking receives and blocking sends.
Takeaway
In general, use nonblocking operations and delay synchronizing with other processes for the best performance. Unintended synchronizations through MPI communication or otherwise lead to delays and can cause imbalance in your code, resulting in wasted cycles.
-
Even before calling
MPI_Waitall, MPI can progress outstanding receive operations either in the background, or each time the user passes control of the execution to the MPI library. In the example, MPI can progress outstanding posted receives inside each call toMPI_Send. We discuss the topic of progress in more detail in Ensuring Progress for MPI Nonblocking Operations. ↩