Ensuring Progress for MPI Nonblocking Operations
Video Summary
The below video is a short summary of the article in presentation format. Read on for more details and also links to related work and example codes.
Background
In this guide we are going to discuss the concept of MPI progress for nonblocking operations. First, we define communication progress and why it matters. Next we look at common misconceptions about MPI progress. Lastly, we demonstrate strategies for ensuring efficient and performant progress is made in your MPI application.
Communication Progress
MPI defines numerous nonblocking communication primitives. These operations do not block the calling process based on the completion status of the request returned to the user. The actual advancement of the communication, e.g. protocol handshake, copying of data to/from system buffers or shared memory, or transmission over a network is part of the operation’s progress to completion.
MPI Weak Progress Model
MPI is free to progress communication requests after the initiating call
has returned, but it is not required. That is, a standard-compliant
implementation is allowed to do nothing to progress outstanding
communication unless the user makes additional MPI calls, e.g. to
MPI_Test or MPI_Wait. This is commonly known as the weak
progress model in MPI. An implementation which provides strong
progress will progress communication in the background through the use
of dedicated hardware or software resources (e.g. background
threads). However the cost of strong progress can outweigh the benefits
for applications, which is why MPI does not require it.
Users often find the weak progress model surprising because they assume that starting a nonblocking operation implies asynchronous data movement. In other words, they expect that once a communication operation is started, MPI will work in the background on the request.
Using an example, we will look at the consequences of weak progress on applications and offer solutions to avoid progress stalls.
Example
Consider a simplistic example where 2 processes do some computational
work after starting communication. In this case, rank 0 in
MPI_COMM_WORLD is the sender, and rank 1 is the receiver. The size of
the message being sent/received is 1GB. The function do_work simulates
a computation phase of the application. The full code and associated
Makefile is located here.
/* start communication */
if (rank == 0) {
MPI_Isend(buf, COUNT, MPI_BYTE, 1, 0, MPI_COMM_WORLD, &req);
} else if (rank == 1) {
MPI_Irecv(buf, COUNT, MPI_BYTE, 0, 0, MPI_COMM_WORLD, &req);
}
/* overlap computation with communication */
do_work(&req);
/* complete communication */
MPI_Wait(&req, MPI_STATUS_IGNORE);
Running make in the example directory will build three version of the example.
async1:do_workis a no-op. This version is purely communication.async1-s:do_worksimulates computation by callingsleep(100000). This causes the process to wait for one tenth of a second before callingMPI_Wait.async1-t:do_workalso simulates computation for a tenth of a second, but breaks it into two phases with a call toMPI_Testin between.
Experiments
Let’s look at the output of these three programs on the ALCF Polaris system at Argonne National Laboratory.
Intranode (both ranks located on the same host):
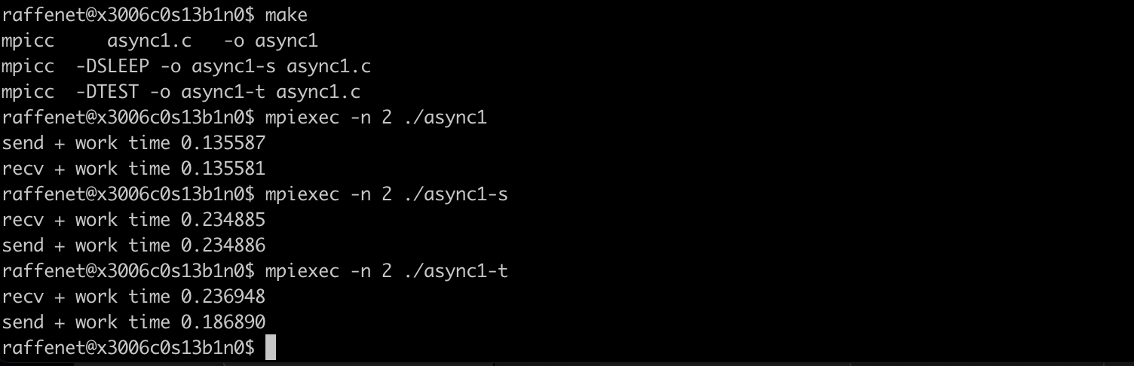
We can draw conclusions about the progress provided by the MPI
implementation based on the timing output observed for each
example. First, for the version where do_work is a no-op, the reported
time is simply the time needed for the communication to complete. From
there, we can see that for intranode transfers, asynchronous progress is
not provided by MPI. We come to this conclusion because we know that
do_work performs a sleep(100000). In the example output, the total
communication + computation time is simply the sum of the two individual
phases.
For the case where do_work calls MPI_Test halfway through its
computation, we do see a reduced overall time for the sender process! By
passing execution control to MPI through the use of MPI_Test, the
sender-side communication is able to overlap with the computation and
complete in less time than the sum of the two phases.
Implementation of Intranode Communication by MPI
In order to understand the results, we need to consider how a MPI
implementation performs an intranode transfer. Modern MPI libraries
typically transfer data within a node over shared memory1. MPI will
internally set aside memory for communication purposes and map it into
the address space of all processes within a node either during
MPI_Init or possibly communicator creation.
At communication time, message size dictates the underlying protocol used for communication. For small messages, so-called eager protocol is used. A shared buffer is filled by the sender and directly enqueued to the receiver. When the receiver matches the message, it copies the data from the shared data buffer to the user buffer and completes the operation. Messages larger than the eager threshold most often employ rendezvous protocol. Rendezvous first involves a handshake between send and receiver to avoid consuming limited resources before they will be used. Only after the ready-to-send (RTS) and clear-to-send (CTS) handshake has been performed is data copied to shared buffers and consumed by the receiver.

The message size in our example far exceeds the typical eager size, so
we should assume rendezvous is used. MPI_Isend causes a CTS message to
be sent to the receiver, after which the sender process proceeds to call
do_work. In each case where MPI_Test is not used, it is likely that
the CTS message from receiver to sender is not received until MPI_Wait
is called, meaning that they actual data movement does not start until
then. With a large message size, data movement dominates the
communication time and thus we see the overall communication plus
computation as the sum of the individual parts.
By breaking up the computation phase and calling MPI_Test, MPI has the
opportunity to advance the rendezvous protocol and potentially start
data transfer before MPI_Wait. The resulting communication plus
computation time is less than the sum of its individual parts (for the
sender).
Internode (ranks located on separate hosts):
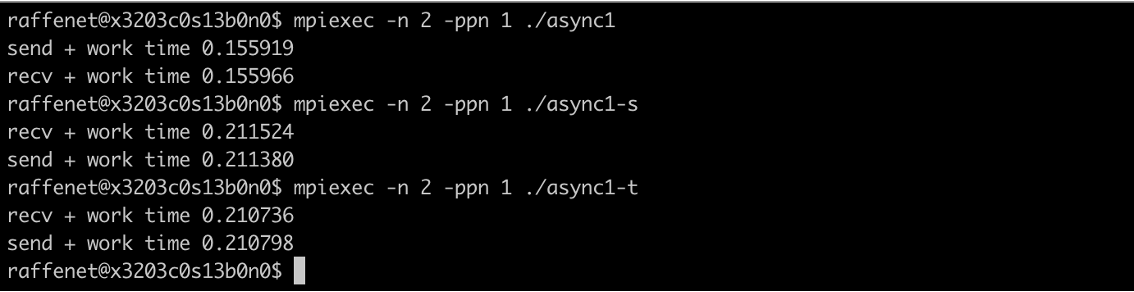
Now let’s look at the internode results of the same program. In this
case, there is no difference between the sleep(100000) version and the
sleep(50000);MPI_Test(&req,...);sleep(50000) version. The reason being
that on Polaris, the Slingshot interconnect does provide some level of
asynchronous progress not present when doing intranode communication. We
observe that in both scenarios, the overall communication plus
computation time is less than the sum of their individual parts, and
functionally the same whether we call MPI_Test or not.
Importantly, it should be noted that there is essentially no penalty for
calling MPI_Test in this example. So whether or not there is an
expectation of progress from the MPI implementation, it should be safe
to add occassional calls to MPI_Test with the intent of ensuring
progress on a variety of systems to achieve the best performance.
Takeaway
Do not assume that MPI communication will progress in the background
once started. If performaning computation after starting a communication
operation, insert periodic calls to MPI_Test[any|some|all] to give MPI
the opportunity to make progress. This will ensure your application
performs well anywhere it runs, since the added calls impose minimal
overhead when asynchronous progress is already provided by the
implementation.