Minimizing Thread Contention Using Communicator Objects
Video Summary
The below video is a short summary of the article in presentation format. Read on for more details and also links to related work and example codes.
Background
The MPI-2 standard defined thread support levels for MPI so that multi-threaded programs could use MPI effectively. These support levels are unchanged in the latest version of the MPI Standard. They are:
MPI_THREAD_SINGLEMPI_THREAD_FUNNELEDMPI_THREAD_SERIALIZEDMPI_THREAD_MULTIPLE
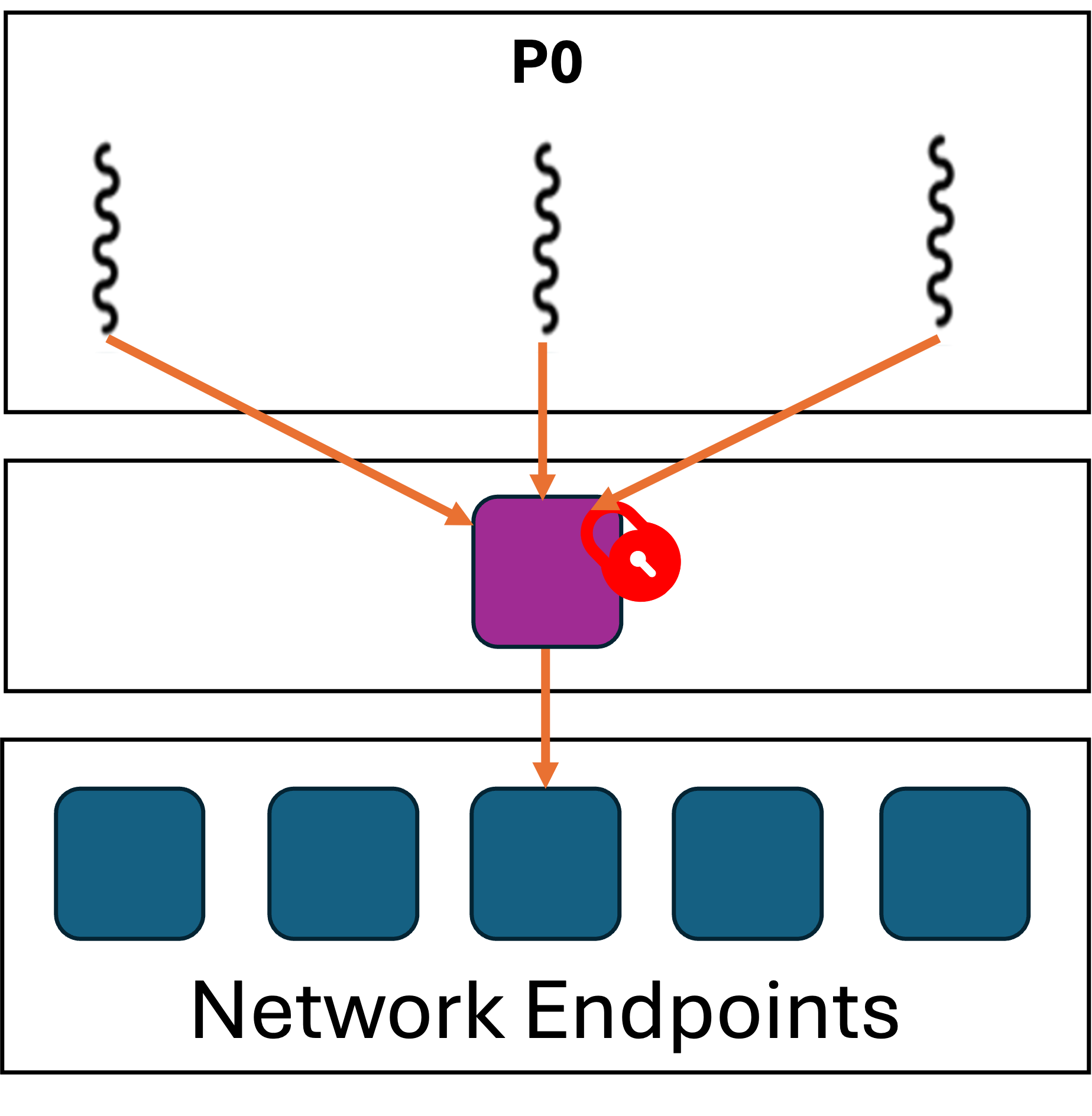
From an implementation perspective, the first three levels are not that different. Each of the three means that MPI is only being called by a single thread at a time. The thread-safety requirements for such usage are minimal, mainly having to do with dependent libraries or operating system interfaces used by MPI. Such external API calls would not commonly be on the data path, therefore they should not impact communication performance.
Poor Historical Performance of MPI_THREAD_MULTIPLE
MPI_THREAD_MULTIPLE is a different story. The MPI specification states
that “multiple threads may call MPI, with no restrictions”. Thread-safe
MPI libraries must identify code paths where shared resources are
accessed and add protection to prevent data races or corruption. For
communication resources like shared memory or network queues, accesses
from multiple threads concurrently results in lock contention and
dramatically reduced communication throughput1.
For years following MPI-2, MPI_THREAD_MULTIPLE was known to have
performance issues. Users (and implementors) tended to stick with “MPI
everywhere” for the best performance. But as core counts grew, the
amount of memory per core shrank from generation to generation of
machine. Users understandably became tempted by multithreaded
optimization to reduce memory pressure on their applications. If those
applications attempted to scale out2 using MPI concurrently, they
would come to know the bottlenecks associated with lock contention.
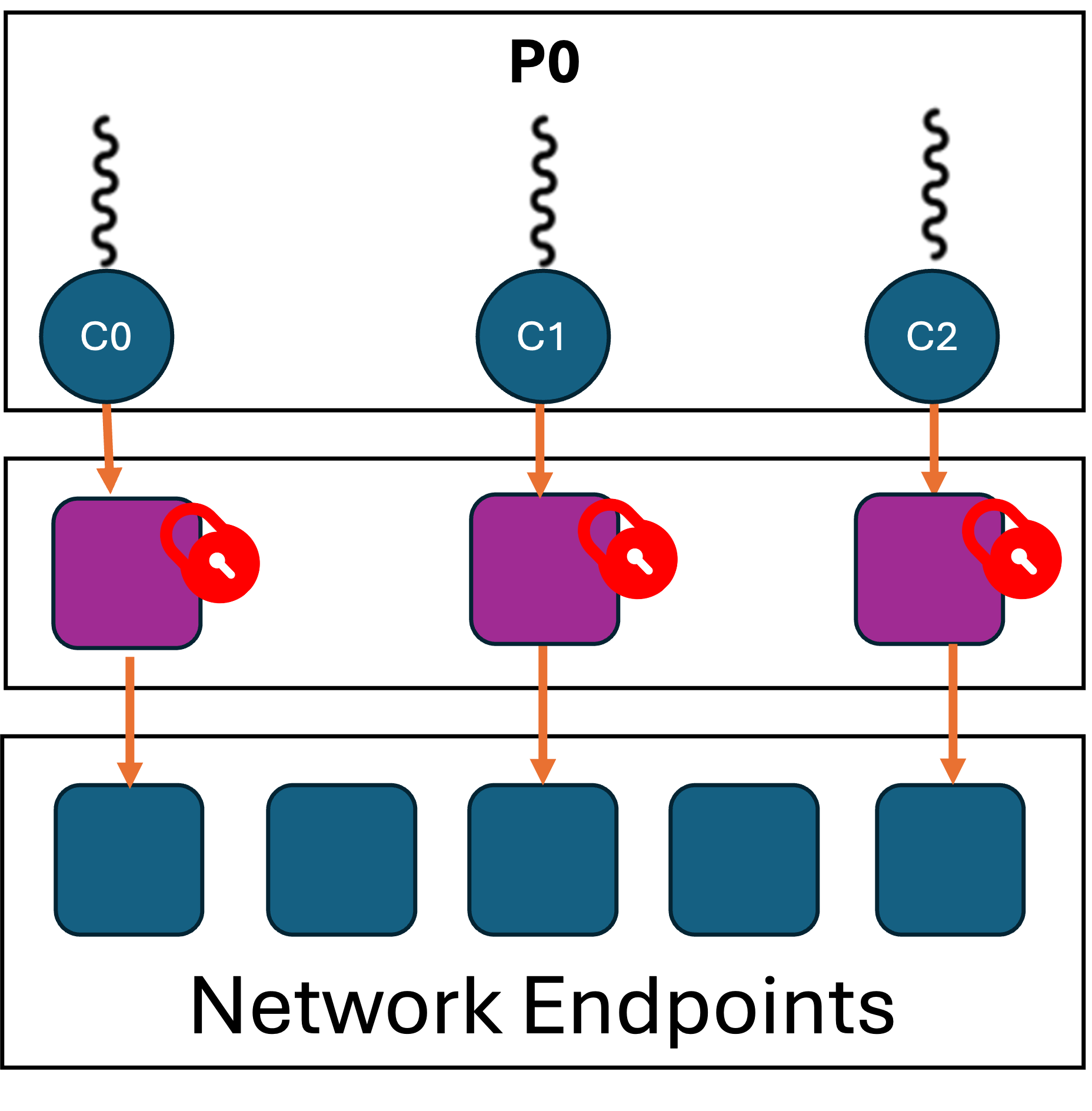
Research into mitigating the contention caused by concurrent access to shared resources continues, but an alternative approach emerged to expose isolated resources from MPI. MPI could internally maintain multiple communication “contexts” which are functionally independent from one another. By carefully mapping accesses to MPI resources at the application-level, one could exploit the independent contexts and recover much of the “MPI everywhere” performance. Importantly, these application changes could be done without any extensions to the MPI API. The MPI standard already provided a convenient resource isolation mechanism in the form of the MPI communicator object3.
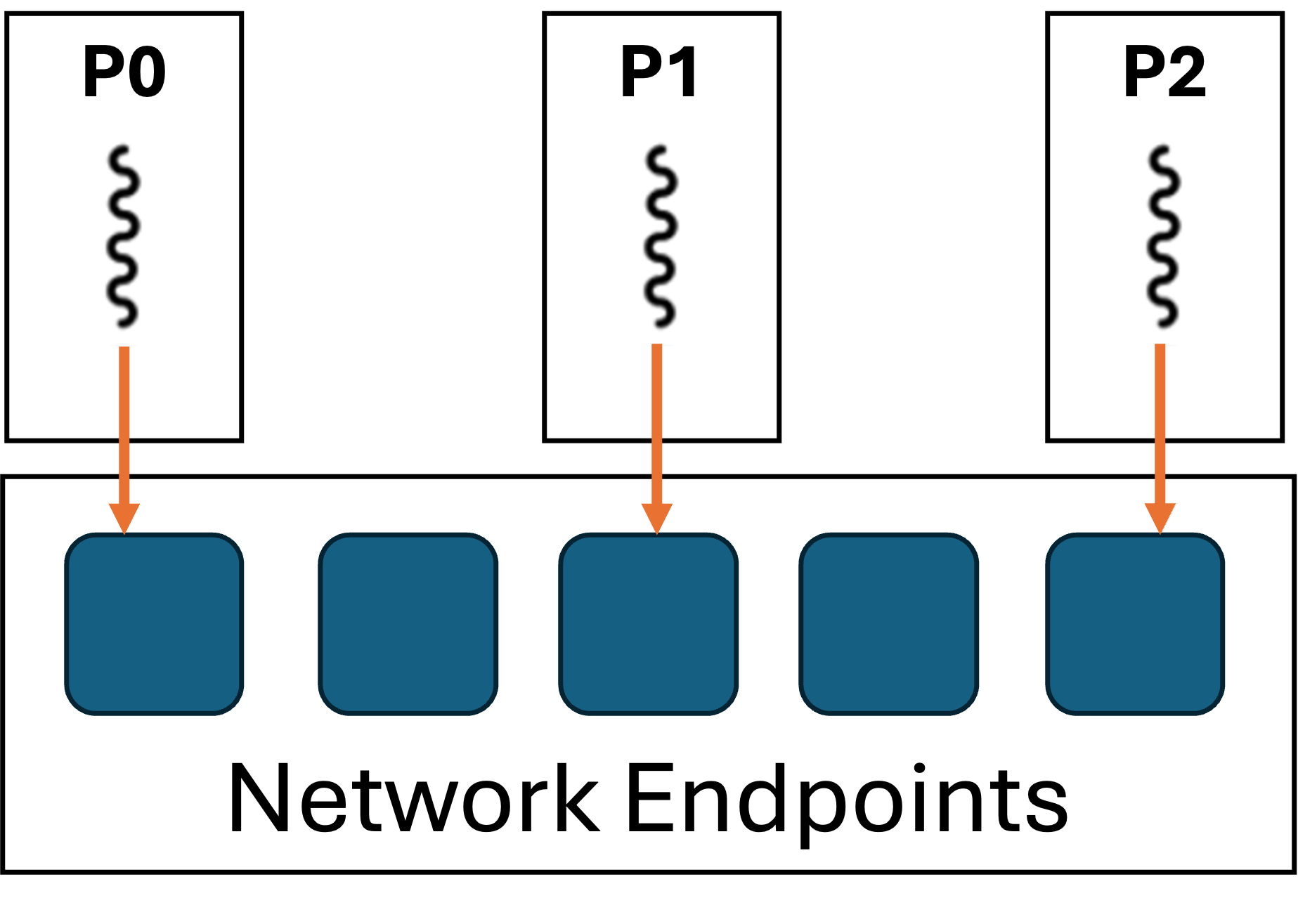
| MPI Everywhere | MPI_THREAD_MULTIPLE | MPI_COMM Per Thread |
|---|---|---|
|
|
|
Multiple MPI implementation support a communicator-per-thread mapping to
provide the best MPI_THREAD_MULTIPLE performance. Because such a
feature can be expensive from a resource perspective, it is often
disabled by default and requires explicit settings in the build or
environment in order to utilize it. In MPICH releases since 4.0, up
to 64 “VCIs” are supported within a single process with the ch4 device
build configuration. Users can specify the actual number of VCIs needed
(default=1) at runtime with the MPIR_CVAR_CH4_NUM_VCIS environment
variable. Intel MPI supports a communicator-per-thread mapping in its
MPI_THREAD_SPLIT programming model.
Example
We can observe the benefits of using separate communicators using by measuring the message rate of single process using one and two threads and contrast that with the same code using a single communicator. For thread parallelism in our example, we utilize OpenMP parallel.
#pragma omp parallel num_threads(n)
{
int tid = omp_get_thread_num();
#ifdef SINGLECOMM
MPI_Comm comm = MPI_COMM_WORLD;
#else
MPI_Comm comm = t_comms[tid];
#endif
void *buf = t_bufs[tid];
MPI_Request requests[WINDOW_SIZE];
double t_start, t_end;
if (rank == 0) {
t_start = MPI_Wtime();
}
for (int i = 0; i < NUM_ITER; i++) {
for (int j = 0; j < WINDOW_SIZE; j++) {
if (rank == 0) {
MPI_Isend(buf, MESSAGE_SIZE, MPI_BYTE, 1, 0, my_comm, &requests[j]);
} else {
MPI_Irecv(buf, MESSAGE_SIZE, MPI_BYTE, 0, 0, my_comm, &requests[j]);
}
}
MPI_Waitall(WINDOW_SIZE, requests, MPI_STATUSES_IGNORE);
}
if (rank == 0) {
t_end = MPI_Wtime();
t_elapsed[tid] = t_end - t_start;
}
}
Experiments
For these experiments we performed runs of the example code using MPICH 4.2.1 and Intel MPI 2021.14 on two nodes of JLSE Skylake.
MPICH
# mpiexec -n 2 -ppn 1 ./mt-p2p-msgrate-singlecomm
Number of messages: 3200
Message size: 8
Window size: 64
Mmsgs/s with one thread: 3.44
Thread Mmsgs/s
0 0.40
1 0.38
Size Threads Mmsgs/s
8 2 0.78
# export MPIR_CVAR_CH4_NUM_VCIS=2
# mpiexec -n 2 -ppn 1 ./mt-p2p-msgrate-multicomm
Number of messages: 3200
Message size: 8
Window size: 64
Mmsgs/s with one thread: 3.64
Thread Mmsgs/s
0 3.35
1 3.31
Size Threads Mmsgs/s
8 2 6.67
Intel MPI
# mpiexec -n 2 -ppn 1 ./mt-p2p-msgrate-singlecomm
Number of messages: 3200
Message size: 8
Window size: 64
Mmsgs/s with one thread: 3.12
Thread Mmsgs/s
0 0.73
1 0.73
Size Threads Mmsgs/s
8 2 1.46
# export I_MPI_THREAD_SPLIT=1
# export I_MPI_THREAD_RUNTIME=openmp
# export OMP_NUM_THREADS=2
# mpiexec -n 2 -ppn 1 ./mt-p2p-msgrate-multicomm
Number of messages: 3200
Message size: 8
Window size: 64
Mmsgs/s with one thread: 3.60
Thread Mmsgs/s
0 2.91
1 2.67
Size Threads Mmsgs/s
8 2 5.58
Takeaway
As you can see, the performance difference between the single and multiple communicator version is drastic. Writing your multithreaded code in this way should give the best performance, but care is still needed to enable the right features at runtime. As always, consult the MPI documentation from your installation, or ask your implementor for more information. If you have suggestions for another MPI implementation, create an issue or submit a pull request!